When you launch Visual Studio the Microsoft Visual Studio 2010 splash screen appears.
Like a lot of splash screens, it provides information about the version of the product and to whom it has been licensed, as shown in Figure given below

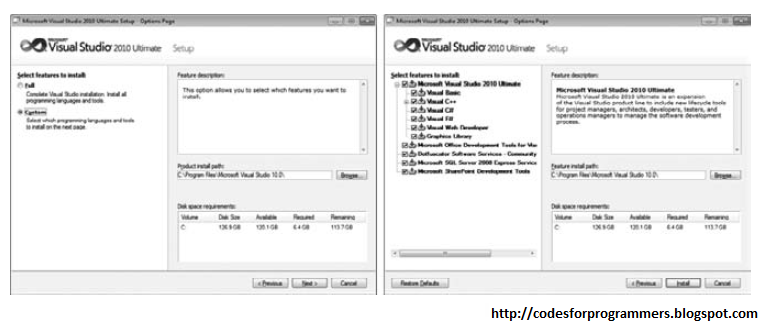
The first time you run Visual Studio 2010, you see the splash screen only for a short period before you are prompted to select the default environment settings. It may seem unusual to ask those who haven ’ t used a product before how they imagine themselves using it. Because Microsoft has consolidated a number of languages and technologies into a single IDE, that IDE must account for the subtle (and sometimes not so subtle) differences in the way developers work.
If you take a moment to review the various options in this list, as shown in Figure below you will fi nd that the environment settings that are affected include the position and visibility of various windows, menus, and toolbars, and even keyboard shortcuts. For example, if you select the General Development Settings option as your default preference, this screen describes the changes that willbe applied. Next covers how you can change your default environment settings at a later stage.

A tip for Visual Basic .NET developers coming from previous versions of Visual
Studio is that they should not use the Visual Basic Development Settings option.This option has been configured for VB6 developers and will only infuriate Visual Basic .NET developers, because they will be used to different shortcut key mappings. We recommend that you use the general development settings,because these will use the standard keyboard mappings without being geared toward another development language.

Regardless of the environment settings you selected, you see the Start Page in the center of the screen.However, the contents of the Start Page and the surrounding tool bars and tool windows can vary.
Before you launch into building your first application, it’s important to take a step back and look at the components that make up the Visual Studio 2010 IDE. Menus and toolbars are positioned along the top of the environment, and a selection of sub windows, or panes, appears on the left,right, and bottom of the main window area. In the center is the main editor space: whenever you open a code file, an XML document, a form, or some other fi le, it appears in this space for editing.With each file you open, a new tab is created so that you can toggle among opened files. On either side of the editor space is a set of tool windows: these areas provide additional contextual information and functionality. In the case of the general developer settings, the default layout includes the Solution Explorer and Class View on the right, and the Server Explorer and Toolbox on the left. The tool windows on the left are in their collapsed, or unpinned , state. If you click a tool window’s title, it expands; it collapses again when it no longer has focus or you move the cursor to another area of the screen. When a tool window is expanded, you see a series of three icons at the top right of the window, similar to those shown in the left image of Figure below.

If you want the tool window to remain in its expanded, or pinned , state, you can click the middle icon, which looks like a pin. The pin rotates 90 degrees to indicate that the window is now pinned.Clicking the third icon, the X, closes the window. If later you want to reopen this or another tool window, you can select it from the View menu.
The right image in Figure above shows the context menu that appears when the fi rst icon, the down arrow, is clicked. Each item in this list represents a different way of arranging the tool window. As you would imagine, the Float option allows the tool window to be placed anywhere on the screen,independent of the main IDE window. This is useful if you have multiple screens, because you can move the various tool windows onto the additional screen, allowing the editor space to use the maximum screen real estate. Selecting the Dock as Tabbed Document option makes the tool window into an additional tab in the editor space.